A TUTORIAL ON CAPTCHA
T. Pavlidis
©2007, 2008
NOTE: This is a tutorial that originated as lectures given at a Stony Brook University seminar course for freshmen in the College of Information Technology. Therefore it is written in a way that assumes little technical background. Readers with background in Computer Vision will probably find the links to other sources more useful than the text. The links were valid as of summer 2007 and many of them have been checked recently.
By clicking the either or both download buttons I state that my intended
use of the
slides is strictly personal and they will not be reproduced for commercial
purposes.
Download Zipped Slides (111KB)
CAPTCHA and HIP
What is CAPTCHA and what is HIP?
When you try to access some web sites you may be asked to type in what
you see in a picture. If you can read the picture the web site assumes
you are human because computers (in this case bots sent by spammers) cannot
read such text. The word CAPTCH is an acronym and stands for
|
Completely Automated Public Turing test to tell Computers and Humans Apart |
 |
CAPTCHA sample taken from Wikipedia's
definition of CAPTCHA |
In order to "read," computers must do Optical Character Recognition (OCR), a process that starts with the pixels of an image and ends by identifying letters. OCR works by first separating the foreground (letter) color from the backround color, then collecting pixels with the letter color into groups so that each group corresponds to a letter, and then trying to figure out the shape of the letter. By 1990 people had written programs that could perfrom these tasks well for some types of text and there are several products in the market that do a good job with printed text using the Roman (or other western) alphabet. (Ironically, by the time the products reached the market the need for OCR had been greatly diminished because most text was entered through computers in the first place.)
CAPTCHA (initiated by researchers at Carnegie Mellon University and IBM in 2000) works by understanding the OCR methods and displaying text that can break them. Of course this a game two can play, so OCR designers can modify their methods to read the distorted text.
While CAPTCHAs started with text they have started using other images
that maybe easy for a human to recognize but they baffle computers. Also,
some of the new tests are not public so the technology is now called HIP
that stands for
Human
Interaction
Proof
While it avoids the historical reference to Turing, it is a shorter acronym and easier to remember.
Alan Turing and the Turing Test
Alan Turing (1912-1954) is considered the inventor of the modern computer. He did both theoretical work and direct development for a computer that was able to break the ENIGMA German codes during World War II. You should read at least a Short Biography by Jerome M. O’Connor. More information can be found in the Wikipedia entry, and even more in a full Biographical page created by Andrew Hodges, author of the book Alan Turing: the enigma (Touchstone, 1983).
A little known fact is that Turing was interested in making computers read. According to Hodges (above book, pp. 402-3) Turing devised a scheme "for computer character recognition, which would involve an elaborate system with a television camera ..." However, the system could not be built with the electronics of that time (1949).
After the first computers were built during WW-II, some people thought of them as "electronic brains" and there was a lot of excitement about their matching of human cognitive abilities. Could we ever build a computer that was truly intelligent, the way a human is. Turing proposed a test for deciding the question. According to a web site devoted to the Turing Test, the test consists of a human interrogator, a machine and another person. "The interrogator is connected to the person and the machine via a terminal, therefore can't see her counterparts. Her task is to find out which of the two candidates is the machine, and which is the human only by asking them questions. If the machine can 'fool' the interrogator, it is intelligent."
In some ways CAPTCHA is a reverse Turing test because we want to disntiguish between people and machines but the underlying issues are the same.
REQUIREMENTS FOR HIP/CAPTCHA
Based on an e-mail from Patrice Simrad of Microsoft Research
If you think of creating a new HIP/CAPTCHA here are some issues to consider
- How easy is it to generate? For hotmail, we need to generate in the order of 1M new different challenges per day. It may seem like a good idea for a HIP to present a picture of a cat or a dog and ask which one it is, but it is completely impractical to obtain 1M different pictures per day Where do we get these images? How do we label them reliably? How do we make sure that no offensive images sneak in? What is the cost of storing them? What is the bandwidth cost? Etc. Character based HIP systems can generate hundreds of new unique HIPs per seconds on one machine.
- The HIP must be resistant to brute force attack. Human can label a HIP at a cost of 1-3 cent per HIP. A computer that does intense visual processing and succeed 1 in 10,000 has about the same cost. An algorithm that lets the computer succeed 1 in 100, reduces the cost to 100 time less, meaning that the HIP is broken.
- The HIP must have a very small cognitive load on the human, otherwise users hate it and just do not use the service.
NON-TEXT CAPTCHA
The possibility that a text CAPTCHA can be defeated has led people to devise other tests, in particular asking people to label images. However, there is problem there: the need for a human to label the pictures in a large database so that answers can be verified. Luis Von Ahn has suggested the use of games (such as ESP) to have people label pictures while playing a game. In text CAPTCHA the text is transformed into a hard to read form automatically. But how about generating pictures automatically so that the computer knows the label already?
One of the most impressive solutions of this type is a 3-D CAPTCHA developed by Michael Kaplan. (Professor Greg Mori of Simon Fraser University directed me to this site.)
The idea is to have a graphic display model for a scene and display a different view each asking the user questions about the scene. Here is a sample of what may be displayed (copied from the above site).
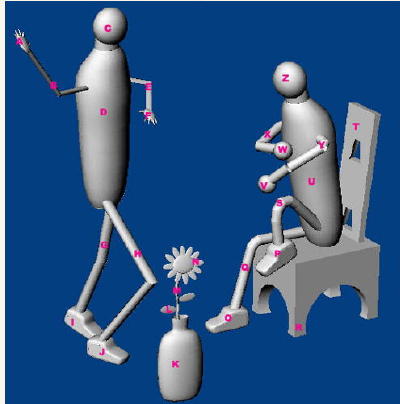
Also the following instruction is displayed: Please click on or enter each letter corresponding to the following list in the field below. You must enter them in the exact sequence listed.

In this case the user must type C and K. The task has been shiften from recognizing letters to analyzing a complex scene that appears well beyond the capacity of what computers can see.
OTHER NON-TEXT CAPTCHA
There are several suggestions posted on the web about other forms of CAPTCHA. Here is a question I posed to my freshman class in the Spring of 2007 and the answer given by Michael Ceyko, one of the students.
Question
Someone proposes as CAPTCHA pictures of, say, cats and asking the user "How many cats do you see in the picture?" Is this a good CAPTCHA? Explain why (or why not).
An answer provided by Michael Ceyko
A CAPTCHA asking how many cats are in the picture could be a good CAPTCHA if a number of measures were taken. Firstly, we would most definitely want the pictures to be of actual cats, and not just drawings or renderings of cats. Otherwise, it may not be complex enough and a good algorithm could defeat it, by say, looking at the outlines of the cats. If the pictures were of real cats, there would be fur and such, so the edges wouldn't be as clearly defined.
Also, we would want the cats to be in different positions, or more specifically, make sure that all the eyes of the cats cannot be seen. The eyes of a cat are a distinct feature of a cat that may be able to be identified by a computer simply because of how different it is than the rest of the cat. Then, by counting the number of eyes, we can determine the number of cats. Such is also true for other distinct features of cats, such as possibly noses or tails. If we ensure that at least some of these parts are not visible on all cats, then we cannot count the number of cats simply by counting the number of a certain part that we see.
Another precaution that we would want to take is to make sure that some of the cats are touching one another, especially some cats of about the same color should be touching each other. This would increase the chances that any algorithm counts multiple cats as the same cat. In a similar precaution, the cats should probably all be of similar colors to the surface they appear on (like a rug), which could further confuse algorithms.
Of course, even with all of the things that we could do, it still doesn't make for the best CAPTCHA. Since we need the picture to be accesible to all, we don't want to make people have to count to an obscenely large number, so the number of cats in the picture has to be limited to, say, 50. Therefore, someone trying to break the CAPTCHA could do so simply by guessing random numbers, and they still have a 1 in 50 chance of passing the CAPTCHA. The reason that random numbers and letters work is that with even 3 characters, there is only a 1 in 46656 that we can guess the correct string by randomness alone.
CAPTCHA and HIP Web Sites
There are several websites that deal with CAPTCHA technology (mainly text).
H. Baird's Research Site The main page of this site provides a good overview of the subject in easy to understand terms. I recommend the paper on "Implicit CAPTCHAs". That should be contrasted with Von Ahn's video (see end of this list).
The CAPTCHA project web site Everything you wanted to know about CAPTCHA and more. You may click on specific links (for example captchas/gimpy) to access various kinds of CAPTCHA and "play around" with them. The site also discusses non-text CAPTCHAs.
The Microsoft Document Processing site contains several papers dealing with HIP or CAPTCHA. Of special interest are those listed below. (In each case a full citation of the paper is given for proper credit. However, you can find the paper on the web without going to the library.)
|
Breaking Some Common HIPs (including those of Yahoo, Google, Ticketmasters, etc). [Kumar Chellapilla, and Patrice Simard (2004), “Using Machine Learning to Break Visual Human Interaction Proofs (HIPs),” Advances in Neural Information Processing Systems 17, Neural Information Processing Systems (NIPS’2004), MIT Press.] Looking for a "sweat spot" to make reading easy for humans but hard for machines [Chellapilla K, Larson K, Simard P, and Czerwinski M (2005), “Designing Human Friendly Human Interaction Proofs (HIPs),” in Conference on Human factors In computing systems, CHI 2005. ACM Press.] The Full Story [Chellapilla K, Larson K, Simard P, and Czerwinski M (2005), “Building Segmentation Based Human friendly Human Interaction Proofs (HIPs),” in Proc. of the Second Intl’ Workshop on Human Interactive Proofs, HIP2005, Springer-Verlag.] Sometimes the Computer Wins. It shows that once humans lose the advantage of context, they can be beaten by computers [Chellapilla K, Larson K, Simard P, and Czerwinski M (2005), “Computers beat Humans at Single Character Recognition in Reading based Human Interaction Proofs (HIPs),” Second Conference on Email and Anti-Spam (CEAS’2005), July 21-22, Stanford University.] |
Pretend Were Not a Turing Computer but a Human Antagonist site (by Sam Hocevar). A lot of examples of CAPTCHAs with interesting discussions. Highly Recommended.
Code Project CAPTCHA The Code Project deals with Visual Studio and .NET code and the CAPTCHA page includes code.
A Site offering protection from Spam It uses CAPTCHA in some of its offerings.
A Video of General Intersest: A 50 minute video covering
CAPTCHA as well as other topics related to this seminar can be found in
a talk by Luis Von Ahn given at Google on July 26 2006. Von Ahn is
a co-inventor of CAPTCHA and the talk uses text CAPTCHA as its starting
point but it covers a lot more. Its title is Human Computation.
Warning: Listen to the sound because the text transciption of
the video is sometimes wrong.
Acknowledgements: I have received help from several people who directed to me to various sources that I used for this tutorial. They are (in alphabetical order): Henry Baird (Lehigh Univ.), Kumar Chellapilla (Microsoft Research), Steven Horowitz (Yahoo Research), Greg Mori (Simon Fraser Univ.), Paul Pavlidis (Univ. of British Columbia), and Patrice Simard (Microsoft Research). I thank Michael Kaplan for giving me permission ro copy some of his material to this site.
Version of March 4, 2008 (slight revisions on May 17, 2008)