Computers versus Humans
Theo Pavlidis
Distinguished Professor Emeritus
Dept. of Computer Science
Background paper for a talk given at the November 1, 2002 Emeriti Faculty Meeting at Stony Brook
University
Latest revision (minor): December 23,
2002.
Abstract
The notion of computers as competing with humans in terms of "intelligence" has been around for a long time and it becomes periodically the focus of public attention, depending on various events. Twenty years ago the cause of attention was the Japanese Fifth Generation project. In 1997 the victory of IBM's Deep Blue over Kasparov generated a fair amount of claims in the popular press that, finally, computers were outsmarting humans. Today face recognition by computer is been discussed both as a help to fight terrorism and as a threat to civil liberties. I plan to provide an overview of the underlying technologies (at a level appropriate for non-specialists) and explain why certain tasks of human intelligence remain well beyond the capacity of computers and are likely to stay that way in the foreseeable future.
Introduction
The first electronic digital computers came into use about sixty years ago, mainly to perform large-scale numerical or combinatorial computations. (Artillery tables in the U.S., code breaking in England.) They were seen by many people as "Electronic Brains" and very soon hopes (or fears) were raised that they could perform all tasks associated with human intelligence besides number crunching or symbol manipulation. Possibilities included mechanical translation, written symbol recognition, speech recognition, game playing, etc. The term Artificial Intelligence (AI) has been used to describe the research area that deals with such problems. Progress has been very slow and both the hopes and the fears have abated but now and then an event occurs that revives the interest of the public (and the funding agencies) to the field.
The victory of the chess machine Deep Blue over Kasparov in 1997 created a certain stir in the news media because of the unwarranted conclusion that a "machine" had bested a human. I will return to this topic, but it suffices to say that the Deep Blue team included an international grandmaster, i.e. a highly skilled human chess player had been involved in the programming of Deep Blue.
Face recognition by computers has received a lot of recent attention recently, both favorable (as helpful for fighting crime/terrorism) and unfavorable (invasion of privacy). I will argue that it is probably of limited, if any, use.
My purpose is to show that we have little to hope or fear from computers taking over the world by replicating human intelligence. This is not to say that computers do not have significant social impacts. For example, credit cards could not exist without computers. Since money problems connected to credit card spending contribute to the dissolution of some marriages we can probably claim that computers have contributed to an increase in the divorce rate. However I will ignore such indirect effects, significant as they might be and focus instead on the possible direct control that can be exerted by "intelligent" machines.
Because of the diversity of the intended audience (ranging from mathematicians to historians to biochemists and artists) this is not meant to be a scholarly paper. My goal is provide a bit more depth than that of the weekly magazines and daily papers.
A Quick Look at Artificial Intelligence
Very early two distinct approaches to Artificial Intelligence (AI) emerged:
1. There were research efforts to built or program a computer modeling the human brain with the hope that such a machine could be taught to perform all these tasks by example and eventually have computers that behave pretty much like humans. Such research usually goes under the names of generalized AI or strong AI.
2. Other researchers thought that a general solution was not feasible, but each specific problem should be addressed as an engineering problem that could be solved using an ordinary computer. The term "Artificial Intelligence" is rarely used for such efforts. Some of them are grouped under "Pattern Recognition" and others under the specific application name such as speech recognition, mechanical translation, etc. However, when there is a need to refer collectively to such research, the terms narrow AI or weak AI are used.
The first approach was the most appealing, at least to the people who had the money, so it received considerable funding. However nontrivial funding was also devoted to projects falling under the second approach. What are the results sixty years later? Very little, if anything has come out of the first approach. Some modest successes have resulted from the second approach, but even those fall short of the early expectations.
Hubert Dreyfus has written a good critique of the first approach. (He is the one who introduced the terms "strong AI" and "weak AI".) His work was first published in 1972 under the title "What Computers can't Do." A new edition appeared in 1992 under the title "What Computers Still can't Do" [D92]. Dreyfus presents solid philosophical and scientific arguments on why the search for (generalized or strong) AI is futile. His book also contains some interesting stories about the social dynamics of the AI researchers. While there have been several other critiques published, such as [P89], Dreyfus work is my favorite. For those who do not wish to invest the time and effort required to follow Dreyfus' arguments I recommend a recent article in Red Herring [J02] that contains a non-technical but quite informative discussion of the subject.
The idea that we can be build a machine that replicates the human brain is so absurd that it would not be worth discussing if it were not for the numerous efforts made toward that goal. The key problem has been lack of understanding of neurophysiology by some mathematicians, engineers, and computer scientists.
For example, great hopes were placed on "Connectionism," namely building a machine with numerous small and simple units, all connected to each other and that would be trained it so that the appropriate connection will be strengthened. There was even a company, called Thinking Machines, formed to build such "connection machines." However, the only customer of the company was the Department of Defense and the end of the cold war signaled also the end of the company. Why would anyone say that a connection machine a model of the brain? Because the brain consists of simple cells, all connected to each other. This may be what one learns in Biology 101, but the brain is highly structured. True, each neuron is connected to several others, but there are billions of them ([D94], [RB98]).
While this approach had some very strong proponents, it was not taken seriously by most scientists. There is a simple question about such a model that must be answered before it can be taken seriously. If you claim you have a machine modeling the human brain how would you modify it to model the brain of a dog, since a dog cannot learn to write poetry, play chess, etc? No one ever provided an answer to the question.
And there were several jokes. For example, "Natural Stupidity will beat any time Artificial Intelligence." There was also an apocryphal story at Bell Labs. At the end of a talk on a model of the brain someone from the audience got up and addressed the speaker: "Sir, this might be a model of your brain, but I can assure you it is not a model of my brain."
It is also worth remembering that there is a history of considering the latest technology as a model of the brain. Thus in the 16th century irrigations networks (with sluice gates) were considered to be models of the brain. Early in the 20th century that role was taken up by telephone exchanges.
The most useful AI results were useful spin-offs of the research; for example, search techniques. Still a lot of money was invested (and wasted) in AI projects. The Red Herring article [J02] mentioned earlier is addressed to venture capitalists warning them to stay away from AI ventures. It contains the interesting statement: "The main function of generalized AI in the real world has always been to create publicity and generate funding for firms that build and sell narrow AI applications."
Neural Nets
Neural nets represent a modest version of AI. The goal is not to solve all problems, but provide a method for solving all classification problems such as recognition of written symbols, speech, medical conditions, etc. It has been shown that neural nets are equivalent (as far as results are concerned) to certain nonparametric statistical classifiers [JMM96]. (They may have advantages in terms of speed though.) Such classifiers have formed the basis for statistical pattern recognition. While this methodology has a certain validity of its own, it also suffers from certain limitations having to do with the need to map the physical world into a feature space, which must then be partitioned into classes.
Example: Suppose that we want to investigate height (H) and weight (W) as predictors of
heart disease. In the diagram of Figure 1 full circles represents people (from a population
sample) who have had a heart attack and empty circles represent those who did not. A
neural net will try to fit a separator between the two, typically the one shown in the
diagram as a thick line. This is the wrong result for several reasons: to start with the
normal weight is not a linear function of height but it should fall somewhere between
cubic and quadratic (shown by thin lines in the diagram). Furthermore, we have
incomplete information because we have ignored other factors that influence heart attacks
(smoking, genetic predisposition, etc) so predictions on the basis of weight versus height
only are of limited value. The weakness of the result is obvious in this case but, in
general, we have little knowledge about what the proper features are.
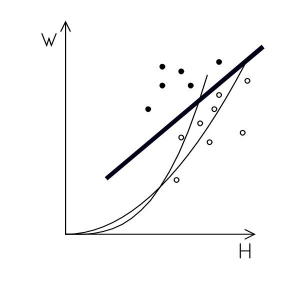
Figure 1: Separating people who had heart attacks (dark circles) from
those who did not (open circles)
We could "play it safe" and use all possible features. For example, if our subject is recognition of written symbols we can select as features the bits of the image of the symbol. A 20 by 30 matrix is usually enough, so we can select 600 features. However, when we work in a high-dimensional space there is the danger that we can construct a spurious separation surface unless the number of data points per category exceeds the number of degrees of freedom by a significant factor. The subject of extracting features from a picture has received a lot of attention, but no general systematic methodology was ever developed. See [S89] for a collection of papers on the subject containing a wide range of ideas.
Strong neural nets advocates tend to minimize the importance of feature extraction because, in principle, by selecting a large number samples we should be able to find a reliable separator. However "large enough" is often well beyond the practical capabilities of the development effort. In contrast, those in favor of focusing on feature extraction point out that if a proper mapping is made from the physical objects to the mathematical space the statistical classifier is of secondary importance. This is illustrated in Figure 2. In the top diagram the two distributions overlap significantly and there is significant difference in performance between an optimal and a sub-optimal separator. In the bottom diagram the distributions do not overlap and there is little difference in the performance of the two classifiers.
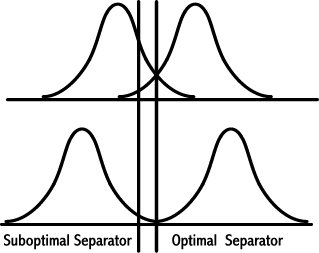
Figure 2: The importance of optimal and sub- optimal separators in
distinguishing between two bell shaped distributions
There is no escaping the need to understand the nature of the problem so that we may construct the proper mathematical model and obtain an estimate of the number of samples needed to estimate the parameters of the separator. Thus statistical classifiers (or neural nets) are useful only if the structure of the problem has been understood. This led to the development of structural pattern recognition that places emphasis on understanding the structure of the problem and obtaining the appropriate mathematical form before applying any statistical techniques. Thus a labeled graph may be a better representation than an array of features.[P77]
An underlying challenge to all classification schemes is the issue of similarity, a concept that it is quite difficult to quantify. Consider, for example, the three shapes in Figure 3.
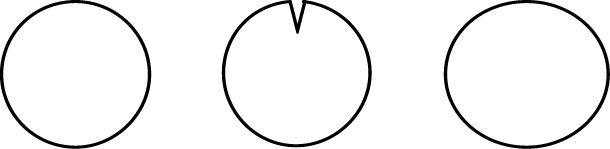
Figure 3: Illustration used to explain the difference between humanly perceived and mathematical similarity
If you ask a person which one of the three shapes does not belong with the other two, most likely the answer will be the middle shape (circle with a notch). But if we use the common integral square error (L2 norm) to find the answer, the result will be the rightmost shape (an ellipse). A Sobolev norm will give an answer similar to that of human perception but one can construct more complex examples where that one also fails.
Non-parametric classifiers and neural nets in particular can be quite useful once the proper mapping of the physical object to a mathematical space has been made. Their main weakness is the exaggerated claims made for them on the basis of spurious biological analogues. In a certain vague way the architecture of a neural net (shown in Figure 4) suggest the architecture of the brain. Jumping from this "similarity" to suggest that the computational device is a model of the brain is as meaningful as suggesting that a table is a model of a dog because both have four legs. The name itself (instead of non-parametric statistics) indicates the emphasis on exaggeration.
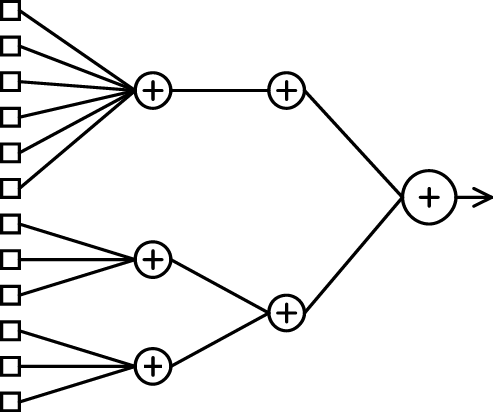
Figure 4: Organization of a neural net (The nodes with the "+" symbols mean taking a weight sum of the inputs. The output of each such node is a nonlinear function of the input.)
During the last few years there have been claims that AI/neural nets are used with success in the web. Consider for example, the program that Amazon uses to guess a customer's preferences and offer suggestions. At its basis are two sets: the set B of books that are been sold and the set of customers C. For each customer c there might be a list b(c) with pointers to the books that the person has bought. Similarly, for each book b there might be a list c(b) with pointers to the customers that bought the book. In Figure 5 books and customers are linked by a line whose color depends on the customer. Either list may be used to create a weighted graph G(B) whose nodes correspond to books and the branch linking two nodes is labeled with the number of customers that bough both books. In Figure 5 the purple line connects two books because both have been bought by the same two customers. A customer graph G(C) has nodes that correspond to customers and branches weighted by the number of books that both customers bought. While theoretically the construction of such graphs is trivial there are significant practical difficulties because of the large size of the sets B and C (in excess of a million). One could use anthropomorphic terms and claim that the system "learns" by observing purchases of books by customers but that would be misleading. All the system does is updating weights of branches in a graph. Recommendations are based on identifying highly connected subgraphs. There is a need for efficient algorithms for performing such a task as well as the need for heuristics that guide parameter selection so building such a system is a challenging engineering task but it would be a gross misnomer to call it an intelligent system.
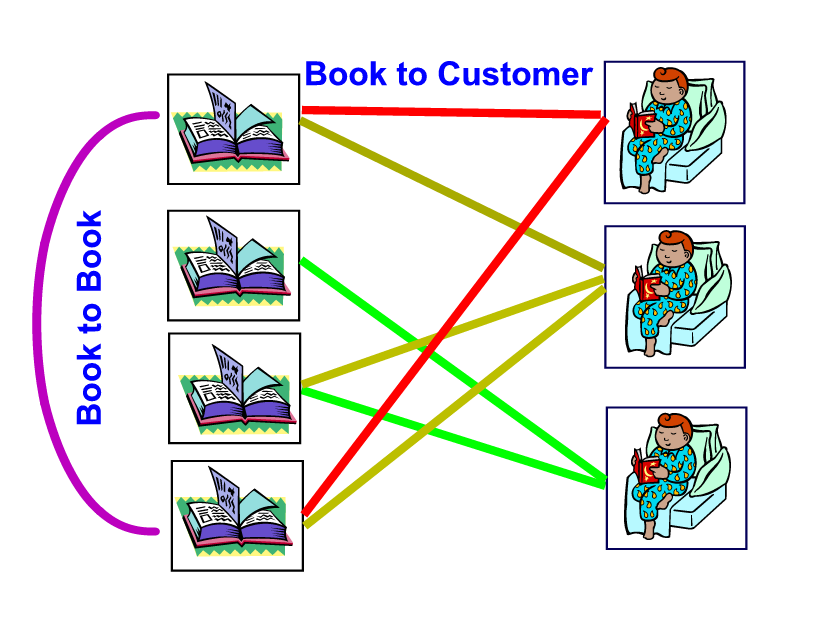
Figure 5: Inferring book categories from purchasing patterns. (Or how Amazon might construct their recommendations)
I cannot help but add a personal story. While I was a graduate student at Berkeley I did some work on neural modeling. It had a more modest goal than modeling the brain; my objective was to model the ganglion controlling the flight of a locust. One day Jerome Letvin visited the department and several graduate students made appointments to ask his opinion about their work. He said that what I was working on might be an interesting mathematical problem, but it had no relation to the nervous system. Then he added that I should keep that information away from the funding agency since I might lose my support if I was truthful. That probably explains the persistence of biological analogues.
The Scalability Issue
A major issue with non-parametric classifiers is that of scalability. Suppose we selected features and "trained" a classifier for 1000 samples from a population. What is the probability that this classifier will perform well for the whole population? We may have found a separator for two classes for the 1000 samples, but how valid is the separator for, say, ten classes and a million samples? Several systems that fared quite well in the laboratory have failed in practice for that reason.
One example is "VeggieVision" developed by IBM. The idea was to recognize vegetables (that are not labeled by bar codes) at checkout counters. It was relatively easy to build a system that could tell tomatoes apart from cucumbers or apples from oranges. It is far more difficult though to distinguish two varieties of oranges from each other to say nothing about distinguishing organically grown tomatoes from conventional ones. Supposedly the system was tested in Australia about two years ago and nothing has been heard about it since then.
Scalability is a key issue in face recognition. There have been several research projects with results that demonstrated successful face recognition. However, the population samples in such projects were relatively small, usually the members of a research laboratory and their friends. Samples were diverse. They included men and women of different races with different hairstyles and, for men, different amounts of facial hair, etc. I have never seen a study where all the subjects share the same major characteristics. For example, white blond men between the ages of 20 and 30 with long hair and beards. In addition, the subjects in such studies were cooperative. Expanding the method to a large and uncooperative population appears daunting.
Recognizing Written Symbols
Recognizing written symbols was probably the first pattern recognition problem to be studied. Hodges [H83] claims that Alan Turing himself was interested in it. He also tells of a visit of Norbert Wiener who told Turing not to waste his time with that problem because it had already been solved by the Neural Nets of McCullough and Pitts at MIT! (Incidentally, those neural nets were quite different in nature than the systems that appeared under the same name 20 years later.) This problem is usually referred to as Optical Character Recognition (OCR) and, in contrast with other AI problems, today we may venture to say that OCR is a "solved" problem. There are several good products in the market although none of the companies that produced them are doing very well financially. The reason for the lack of financial success is that by the time the products reached the market the need for OCR had been greatly diminished.
One of the original markets was archival, converting old printed text into electronic form. There was a great need for that in the 1970s, but OCR technology was not up to the task then. Therefore the conversion was done manually (usually in English speaking third world countries). By the time, good OCR technology became available (around 1990) the archival market was much smaller than before. OCR has been used with some success in postal applications by reading the city, state, and zip code. By 1990 about half of the machine printed mail was successfully recognized. Around that time the US Postal Service started funding efforts towards building a next generation of OCR scanners but the effort was curtailed because the volume of mail had been reduced because of the proliferation of fax and e-mail. The Postal Service decided that they could never write off the cost of the new generation of OCR machines. Another common application, scanning magazine pages has also been diminished because of the web.
It is not a pure coincidence that OCR products came out at the time that the need for them diminished. The algorithms used in the products of the 1990s were known much earlier but they were too complex to be implemented in an economical way with the digital technology of those times. When computer hardware became cheap enough economical implementation of sophisticated algorithms became possible. But at the same time personal computers and the internet became widespread. Collections of papers on the state of OCR and document analysis worldwide in the early 1990s (in both industry and academia) can be found in [PM92] and [BBY92].
We may gain some insight into the difficulties facing replication of human abilities in machines by examining some of the challenges that OCR had to overcome. One of them was the separation of foreground (usually black) from background (usually white). This is trivial for humans but it presents significant problems for a machine for several reasons. There may be illumination variations across the page that humans are very good at ignoring but a machine must find a way to deal with them. Another distortion occurs because of the averaging done by the optical scanning system. Thus narrow dark lines appear with the same intensity as narrow white gaps. In order to deal with this problem it was proposed to attempt recognition of written symbols directly from gray scale. However, by the time results of such efforts came to fruition ([WP93], [RP94]) OCR had lost its commercial promise and it was not cost effective for manufacturers to retool their systems.
Humans are not bothered by that ambiguity because they look at the overall shape of the
letter. Not only they are not bothered by distortions in the shape of a letter, they can
manage to read well, even when they fail to disambiguate a letter. This is because
humans use context. (the reason why proofreading is hard.) It is easy to confirm this by
trying to read a phone book without your glasses. You are likely to do much better in
reading the names (where context exists) than the numbers. Also consider the two
sentences:
New York State lacks proper facilities for the mentally III.
The New York Jets won Superbowl III.
The last word in each sentence is interpreted differently, even though they are identical.
All modern OCR systems use
a spelling checkers/corrector. But his is not enough. Consider, for example, finding the
word "dale" in the output of an OCR system. This is a valid English word, but if the
scanned document is a business letter the word is almost certainly an error. The crossbar
of the letter "t" can be missed so that the word "date" is converted into "dale." On the
other hand if the scanned document is a poem the world "dale" might be the correct one.
Therefore we need broader context than that provided by a spelling checker.
Recognizing Mathematically Defined Symbols
We may contrasts the reading of written symbols with the reading of bar codes. Bar codes are easy to read mechanically because they are mathematically well defined. Numerical values are encoded in a sequence of width ratios, something that can be measured quite easily. Not only the one-dimensional codes that are seen in the super-markets are easy to read but also the two-dimensional symbologies such as those seen on the UPS labels (Maxicode) or the ones seen on the New York drivers licenses and registration stickers (PDF417). Examples are shown in Figure 6. Besides their precise definitions such symbols also include error detection and error correction mechanisms [PSW92].

Figure 6: Example of two-dimensional symbologies
Recognizing Pictorial Patterns
The mechanical extraction of information from images goes under the names of Image Analysis, Computer Vision, Machine Vision, or Robot Vision. There is a wide range of applications where it is desirable to perform such a task: analysis of aerial or satellite imagery to extract information about resources or about construction activity; analysis of medical X-ray images for detection of tumors, analysis of images of industrial products for automatic inspection; etc, etc.
Two broad approaches can be used: 1. We make an assumption about the presence of a particular object at a particular location in the image and we attempt to confirm that hypothesis (Top-down). 2. We make no such assumption and attempt to identify objects from the physical properties of the image, such as intensity and color (Bottom-up).
The top-down approach has several advantages, but it is rarely applicable in practical situations. One interesting case where it has been used successfully is in the reading of the checks sent for payment to American Express. Because payments are supposed to be in full and the amount due is known, the number written on a check is analyzed to confirm whether it matches the amount due or not.
The bottom-up approach has wide applicability, but it faces far more challenging tasks. For example, while the separation of foreground from background can be dealt in a less than optimal way in OCR it must be done correctly in other recognition systems. It is usually called image segmentation since the input image must subdivided into regions that correspond to objects that have to be recognized. Most of the research in this area has focused on subdividing in image into regions of approximately uniform color and intensity with the unspoken assumption that such regions would correspond to objects. Unfortunately this assumption holds only for very special cases: diffuse illumination and objects that are polyhedral. A book by Nalwa [N93] provides a critical overview of the methodologies of machine vision. The lack of a solution to this problem has meant, for example, that movie colorization was a labor-intensive process, so that few, if any, of the companies involved were profitable.
Some people (including myself) hold the opinion that significant progress in image analysis can be made only by combining the bottom-up and top-down approaches [P96]. It appears that this is the way that people actually see and one can make several plausible arguments for the desirability of the approach. However, there are several difficulties in actually implementing such a system, including the need for considerable more computational resources. One successful example of such a combination has been in the reading of postal addresses. A bottom-up method is used to read the city-state-zip code (including, of course, error checking offered by the redundancy of information). Then the postal database is used to identify street addresses that are compatible with the ZIP code and that information is used to extract the street address from the envelope. See [HT98] for a collection of papers that use contextual information for document analysis and in particular one discussing the reading of bank checks [H+98].
In addition to reading text, success in machine vision have been achieved for the most part in controlled environments such as industrial inspection applications. In recent years successful applications have also been found when machine vision is used as an aid rather than as a replacement for human vision. For example, enhanced tele-operation is more effective than autonomous robots.
Face Recognition
Automatic face recognition seems an unlikely problem to be solved by computer for several reasons. It took over forty years to built acceptable quality machines that recognize written symbols; what makes us think that we can solve the much more complex problem of distinguishing human faces? Nobody amongst those responsible for displaying face recognition systems asked that, given the difficulties we have to distinguish, say, an "h" from a "b", how can we expect to achieve the far more difficult problem of distinguish one face from another? While mechanical face recognition might be possible in principle, it represents a drastic leap in technology from what has been achieved so far by machine vision. It is also likely that face recognition may not be solved regardless of general advances in the recognition of pictorial patterns. Neuroscientists ([RB98]) point out that humans have special neural circuitry for face recognition. It is well known that people have trouble recognizing differences amongst people of different races than their own. There is a simple experiment that can be used to show the complexity of human face recognition. Could you try to find out in what way the two images of Figure 7 differ? The task becomes much easier if you look at the picture right side up.
{kind=link}

Figure 7: Illustration of one of the challenges in face recognition
It is instructive to repeat the experiment with the cat pictures of Figure 8. (Right side up version.)
{kind=link}

Figure 8: The effect of the subject on face recognition
Not surprisingly, the results of installed face recognition systems have been dismal. An ACLU press release of May 14, 2002 stated that "interim results of a test of face- recognition surveillance technology … from Palm Beach International Airport confirm previous results showing that the technology is ineffective." The release went on to say that: "Even with recent, high quality photographs and subjects who were not trying to fool the system, the face-recognition technology was less accurate than a coin toss. Under real world conditions, Osama Bin Laden himself could easily evade a face recognition system. … It hardly takes a genius of disguise to trick this system. All a terrorist would have to do, it seems, is put on eyeglasses or turn his head a little to the side." ([ACLU]) Similar conclusions appeared in a Boston Globe article of August 5, 2002. It quotes the director of security consulting firm saying that the "technology was not ready for prime time yet.'' He added that the " systems produced a high level of false positives, requiring an airport worker to visually examine each passenger and clear him for boarding." The article goes on to say: "One of the biggest deployments of the technology has occurred in England, in the London borough of Newham. Officials there claim that the installation of 300 facial-recognition cameras in public areas has led to a reduction in crime. However, they admit that the system has yet to result in a single arrest." A recent criticism of mechanical face recognition appeared in the October 26, 2002 issue of the Economist. Ignoring the scientific evidence has resulted in a curious situation. The suppliers of the face recognition systems insist that the testers need to prove beyond reasonable doubt that their systems are faulty, instead of themselves having to prove that they are selling a valid product.
There is web site that displays results of a program for face detection, i.e. locating the face or faces in an image, a necessary step before attempting face recognition. The results are anything but impressive. Apparently the program uses a heuristic that a face is a light round area with dark spots (for eyes, nose and mouth) that causes it to miss faces that are dark and picks up other irrelevant areas. Wearing glasses seems to cause problems because it interferes with the eyes heuristic. Figure 9 shows a blatant case of erroneous results.

Figure 9: Results of the Robotics Institute, CMU program. A green rectangle is overlaid on any face detected. A major miss is evident.
Chess Playing Machines
Chess is a deterministic game, so in theory a computer could derive a winning solution mathematically by generating all possible moves. Because the number of all possible positions is truly astronomical (10120) the amount of computation is too large even for our most powerful machines. Using even the fastest available computer today it will take billions of years to consider all possible moves and, consequently, derive a wining strategy automatically. Ordinary players look only 2-3 moves ahead, skilled players may look 10 or even 20 moves ahead. Such players can do that because they are very good at pruning, i.e. ignoring moves that are not promising. Therefore at each step they consider very few possible moves (often only one!).
Early efforts on computer chess were driven by general AI methodology and focused on imitating the human way of play. (The research efforts were justified to the funding agencies by the claim that playing winning chess was just a special case of general problem solving.) The 1982 edition of Encyclopedia Britannica devotes half a page to computer chess and quotes the dispute between former world champions Botvinnik and Euwe on whether a computer could ever beat a human in chess. A major breakthrough came in the early 1980s when Ken Thompson (the creator of Unix) decided to follow a different approach and have a computer play in a fundamentally different way than the way people play. Thompson developed a chess playing program called Belle based on a minicomputer with a hardware attachment used to generate moves very fast. He did not use any special strategies or heuristics except for a book for openings and end games. Belle defeated all other computer programs and became the world champion. Pretty soon Thompson's approach to the problem was followed by other researchers. The key was to use special chess knowledge and special purpose hardware. The computers looks ahead by considering all possible combinations (without pruning) for a limited number of moves. Belle looked ahead for six moves. An evaluation function is used to select one of the positions at the end and then the move that will lead to that position. While Thompson himself was not a strong chess player many subsequent efforts involved chess experts who worked on developing better evaluation functions.
Since computers can be made to play good chess by using a brute force approach their dominance over human players became a matter of time. Such a dominance though would have no implications about human intelligence. Chess in an exact mechanical game that becomes inexact only because of the large number of combinations, so it presents challenges to human intelligence. If a fast enough machine is built that can handle chess as an exact game it will play it in a completely different way than human players do.
Deep Blue [DBW] made extensive use of special purpose hardware (it could evaluate up to 200 million positions a second) and the expertise of Joel Benjamin, an international grandmaster (he played Kasparov to a draw in 1994) as well as that of another strong chess player, Murray Campbell. At least one member of the team has described their program as using the computer as a tool to enhance the abilities of a human player. The effort was justified within IBM because of the investigation of the special purpose hardware. Thus a computer did not defeat the human world chess champion, but another human did with the help of a computer. (The computer adds a few hundred points to a person's chess rating.) There is a page in the Deep Blue Web site [DBvK] comparing how Deep Blue and Kasparov play chess. It lists 10 points of contrast and I repeat one of them (No. 5) here:
"Garry Kasparov is able to learn and adapt very quickly from his own successes and mistakes. -- Deep Blue, as it stands today, is not a 'learning system.' It is therefore not capable of utilizing artificial intelligence to either learn from its opponent or 'think' about the current position of the chessboard."
At the time of this writing (October 2002) a chess match between a German program called Deep Fritz and the current world champion V. Kramnick had just concluded in a overall draw with each player having 4 points. Deep Fritz does not rely on special purpose hardware, so it can examine only 2.5 million positions a second. It tries to make for its slower speed (compared to Deep Blue) by using pruning. Kramnik stated that he has a lot of respect for the program and the team behind it. [DFK].
Concluding Remarks
Before we attempt to built a machine to achieve a goal we must ask ourselves whether that goal is realistic, and if so whether our effort justifies its cost. To start with, we need to check whether our goal is compatible with the laws of nature (as we know them). Unfortunately, we witness many schemes that claim to achieve goals that violate the laws of physics, such as the various perpetual motion machine schemes. While we see articles that point out the impossibility of such schemes, we do not see similar criticism on various Artificial Intelligence scheme. Part of the reason may be that the AI as well as Computer Science in general is a new field without well defined standards such as they exist in the older Physical Sciences. There are relatively few things that have been proven rigorously to be impossible [H00]. There is a larger class of problems (the class of NP complete problems) where there is a broadly shared opinion, but no proof, that no problem in this class can be solved in an efficient way (H00). Some Computer scientists look with admiration to Chemistry for resolving the issue of Cold Fusion within a year.
In spite of the lack of a rigorous theoretical basis, we can always ask some relevant questions. For example, how important is a task in terms of natural selection? Adding long lists of numbers does not seem to offer any selective advantages, so we may expect computers to outperform humans. On the other being able to distinguish an edible plant from a poisonous one has obvious significance, thus humans are going to be much better at subtle visual cues than computers. The fact that people can perform a particular task is no evidence that it can be performed by computers since we are dealing with two systems of vastly different abilities. The usual answer of purveyors of "solutions" is that "we have proprietary technology that simulates the human brain," etc. It seems that instead of raising a red flag such answers have a seductive effect on people with money to spend, to say nothing of the news media.
A major culprit for pursuing of unrealistic goals is that basic research (as opposed to applied research or development) has often been funded by "mission oriented" agencies, usually with minimal scientific oversight. But the deep roots of the problem go beyond that to the human weakness to try to obtain something for nothing. Artificial Intelligence offered the promise of solving problems without understanding them. In this sense AI shares some of the features of Cold Fusion and other instances of pathological science, as described by Langmuir in his famous talk 50 years ago [L53]. Amongst other topics, he discussed UFOs and he concluded that in spite of the plethora of simple explanations for the observed phenomena, the story of visits by aliens was too good for the news media to let go, so he correctly predicted that it would be with us for a long time. The view of computers as giant brains that are able to out-think and replace humans is about as valid as visits by extraterrestrials, but it makes too good a story for the news media to let go, so we are going to be stuck with such stories for a long time.
Acknowledgements
I want to thank Prof. Kostas Daniilidis of the Univ. of Pennsylvania for bringing to my attention the Red Herring article on AI [J02]. He and Dr. Kevin Hunter of Neomedia made several other helpful comments on the original draft. I learned about comparisons of inverted pictures of faces from a lecture by Prof. John E. Dowling of Harvard University. I should add that I take full responsibility for all opinions expressed in this paper.
Literature Cited
g- Works of general interestc- Works on chess playing computers
d- Works specific to document analysis
g-{ACLU] American Civil Liberties Web Site
d-[BBY92] H.S. Baird, H, Bunke, and K. Yamamoto Structured Document Analysis Springer-Verlag, 1992.
g-[D94] Antonio R. Damasio Decartes' Error: Emotion, Reason, and the Human Brain, Avon Books, 1994.
c-[DBW] Deep Blue Web Site Also The people behind Deep Blue
c-[DBvK] Deep Blue vs Kasparov comparison
c-[DFK] Deep Fritz and Kramnik
g-[D92] Hubert L. Dreyfus What Computers Still Can't Do: A Critique of Artificial Reason, MIT Press, 1992.
g-[H00] David Harel Computers Ltd. what they really can't do, Oxford, 2000.
g-[H83] Andrew Hodges Alan Turing: the enigma, Touchtone, 1983, pp. 404, 411.
d-[HT98] Jonathan J. Hull and Suzanne L. Taylor Document Analysis Systems II, World Scientific, 1998.
d-[H+98] G. F. Houle et al "A Multi-Layered Corroboration-Based Check Reader," in [HT98], pp. 137-174.
g-[JMM96] A.K. Jain, J. Mao, and M. Mohiuddin "Neural Networks: A Tutorial", IEEE Computer, Vol. 29, 3, pp. 31-44, March 1996.
g-[J02] G. James "Out of their minds" Red Herring, August 23, 2002. On the web
g-[L53] I. Langmuir "Pathological Science" Colloquium at the General Electric Knolls Research Laboratory, December 18, 1953. On the web.
g-[N93] Vishvjit S. Nalwa A Guided Tour of Computer Vision, Addison-Wesley, 1993.
d-[PM92] T. Pavlidis and S. Mori (guest editors) of special issue of IEEE Proceedings on Optical Character Recognition (July 1992).
d-[PSW92] T. Pavlidis, J. Swartz, and Y. P. Wang ``Information Encoding with Two- Dimensional Bar-Codes,'' IEEE Computer Magazine, 25 (June 1992), pp. 18-28.
g-[P89] Roger Penrose The Emperor's New Mind, Oxford Univ. Press, 1989.
d-[RP94] J. Rocha and T. Pavlidis ``A Shape Analysis Model with Applications to a Character Recognition System,'' IEEE Trans. on Pattern Analysis and Machine Intelligence, 16 (April 1994), pp. 393-404.
d-[P96] T. Pavlidis ``Challenges in Document Recognition: Bottom Up and Top Down Processes,'' Proc. Intern. Conference on Pattern Recognition, Vienna, Austria, Aug. 1996, vol. D, pp. 500-504 (invited paper).
g-[RB98] V. S. Ramachandran and Sandra Blakeslee Phantoms in the Brain, William Morrow, 1998.
d-[S89] J. C. Simon, editor From Pixels to Features, North Holland, 1989.
d-[WP93] L. Wang and T. Pavlidis ``Direct Gray Scale Extraction of Features for Character Recognition'' IEEE Trans. on Pattern Analysis and Machine Intelligence, 15 (Oct. 1993), pp. 1053-1067.