Limitations of Content-based Image Retrieval
Theo Pavlidis
© Copyright 2008
Version of June 24, 2008
(latest minor editing: October 24, 2008)
Abstract
This is a viewpoint paper where I discuss my impressions from the current state of the art and then I express opinions on what might be fruitful approaches. I find the current results in CBIR very limited in spite of over 20 years of research efforts. Certainly, I am not the only one who thinks that way, the lead editorial of a recent special issue of the IEEE Proceedings on multimedia retrieval was titled "The Holy Grail of Multimedia Information Retrieval: So Close or Yet So Far Away?"
I offer certain reasons for this state of affairs, especially for the discrepancy between high quality results shown in papers and poorer results in practice. The main reason seems to be that the lessons about feature selection and the "curse of dimensionality" in pattern recognition have been ignored in CBIR. Because there is little connection between pixel statistics and the human interpretation of an image (the "semantic gap") the use of large number of generic features makes highly likely that results will not be scalable, i.e. they will not hold on collections of images other than the ones used during the development of the method. In other words, the transformation from images to features (or other descriptors) is many-to-one and when the data set is relatively small, there are no collisions. But as the size of the set increases unrelated images are likely to be mapped into the same features.
I propose that generic CBIR will have to wait both for algorithmic advances in image understanding and advances in computer hardware. In the meantime I suggest that efforts should be focused on retrieval of images in specific applications where it is feasible to derive semantically meaningful features.
There are two appendices with examples of image retrieval. One presents the results obtained from some on line systems and the other presents some experiments I conducted to demonstrate how a method that yields impressive results in the author(s) paper gives poor results in independent tests. I have included a set of images that provide a challenge to the current CBIR methodologies. Two other appendices illustrate the severe limitations of color and edge strength histograms respectively for image characterization.
Related Links: Main CBIR page - A Challenge to CBIR Techniques - Dealing with the Challenge - "The Holy Grail of Multimedia Information Retrieval: So Close or Yet So Far Away?" - An Answer (Three page summary of this document) - An Evaluation of SIFT
Main page of theopavlidis.com - Site map
Timeline: First draft (with a different title): June 2007. Second draft: May 14, 2008. Third and Final draft: June, 2008. (The date in parentheses at the top reflects the last time any minor revisions were made.)
Table of Contents
| Section 1. | Introduction | |
| Section 2. | The Problem | |
| Section 3. | The Curse of Dimensionality and the lack of Scalability | |
| Section 4. | The Role of Context | |
| Section 5. | Why is Image Retrieval so Hard Compared to Text Retrieval | |
| Section 6. | What Can We Learn from Success in Other Areas | |
| Section 7. | What to Do | |
| Section 8. | Conclusions | |
| Section 9. | Acknowledgements | |
| Section 10. | Sources Cited | |
| Appendix A. | Web Test Results of Content-based Image Retrieval | |
| Appendix B. | Simulating What is Happening in Current CBIR systems | |
| Appendix C. | Color Histograms Provide No Semantic Information | |
| Appendix D. | Edge Strength Histograms Provide No Semantic Information Either |
1. Introduction
In October of 1998 I attended the VLBV98 workshop in Urbana-Champaign that included several papers on video indexing and content-based image retrieval (CBIR). (The overall topic of the workshop was Very Large Bit rate Video.) I recall an informal discussion with a few colleagues from the image processing and image analysis areas where we concluded that CBIR was hopeless and only labeling of video (and image) databases offered a promise. We concluded that given the cost of creating these databases, the additional cost for labeling would be comparatively minor.
That put the subject of CBIR off my mind until late in 2005 when one of our dogs (Lucy) died and my wife ask me to find all pictures I had of the dog so that she could put them in an album. That was not an easy task given that I have a personal collection on my PC of several thousands of pictures, very few of them labeled. As a result I started looking for image retrieval tools on the web and looking at the scientific literature. I was sorely disappointed. Not only there were no tools that I could use on my collection, but also there were too few publicly available demonstrations. While there have been numerous publications in this area, I found only three systems that allowed online testing of the authors' methodologies and all three produced quite poor results (see Appendix A). At first this was puzzling because the papers describing the methodologies presented, what seemed to be, impressive results but soon I realized that the papers did not deal with realistic situations. For example, asking to find "all images with a lot of red" is easily answered if the features include information about the color histogram but that is not a particularly interesting query. There were also deeper flaws in the methodologies that I will discuss in the next section.
Clearly, if the pictures in the database are unlabeled a good way to deal with such a query is to find one picture of the subject and ask for pictures similar to the chosen one. It is not only private collections that are likely to be unlabeled. The problem occurs even in public, supposedly tagged databases. When an individual moves suddenly to prominence, it is highly unlikely that images of the person would have been tagged. A notorious instance of such a search occurred during the president Clinton impeachment proceedings when reporters were looking for pictures of the president with Monica Lewinski. Therefore the problem of retrieval by example without relying on tags is not going to go away in spite of what some of us thought during VLBV98.
In my case, I did the best I could with a manual search but I then I wrote a simple CBIR program based on published methodologies and I tested it. While the results were disappointing for the specific task, they provided some insight on why impressive published results are followed by practical results of poor quality (see Appendix B). My test showed that certain methodologies suffer from a lack of scalability. I discuss in the sequel why this might be an inherent problem in the way current CBIR research is conducted.
In this document I use the term CBIR in a sense that parallels text retrieval.
The query is an image and the user wishes to find images in the database
that contain objects present in the query image. The
images retrieved may be quite different from the query image as long as
they contain the objects of interest. This is sometimes referred to as
search for objects (e.g. [SZ08]) to distinguish it with methods that attempt
to match whole images.
Back to the Table of Contents
2. The Problem
Many people agree that content-based image retrieval (CBIR) remains well behind content-based text retrieval. For example, [YSGB05] states "current image retrieval methods are well off the required mark" and [HSHZ04] states "the semantic gap between the user's needs and the capability of CBIR algorithms remains significant." [DAL08] states "Research as reported in the scientific literature, however, has not made significant inroads as medical CBIR applications incorporated into routine clinical medicine or medical research." The editorial for a recent IEEE Proceedings special issue on Multimedia Information Retrieval was titled "The Holy Grail of Multimedia Information Retrieval: So Close or Yet So Far Away?" [HLMS08]
Significant effort has been put into using low-level image properties such as color and texture. Simpler methods use them as part of global statistics (histograms) over the whole image (some methods even forego such characterizations and rely on global transforms such as wavelets.). More advanced methods [CBGM02, CMMPY00, SZ08] use them to describe regions of an image. Even when sophisticated features such as SIFT [Lo04] are used, they still rely on pixel values.
Several authors point to the existence of a semantic gap (for example, [SWSGJ00], [RMV07], and [HLMS08]) as that between the pixel values and the interpretation of the image. Personally I think that we deal with a semantic abyss. The semantic interpretation of an image has very little to do with statistics of the values of the pixels. Figures F1 and F2 illustrate this issue but it should be a familiar topic to anyone who has used histogram equalization for image enhancement. Images tend to maintain their semantics even though their luminance or color histograms are made flat. (See Appendix C for examples.) Histograms of other image properties also seem to lack semantic information. (See Appendix D for examples.)
|
|
|
|
A | B | C |
| Figure F1: The picture in the middle (B) is
a brightened version of the picture on the left (A) but two different
sets of feature measures classify it as being closer to the picture
on the right (C). (See Appendix B about
details.) The values were: |
||



Part of the problem is that representing an image by simple features usually results in loss of information so that different pictures may map onto the same set of features. If an image has area A and each pixel has L possible levels, then there are LA such images possible. On the other hand the number of possible histograms is less than AL. Usually the perceptually significant L is much smaller than A so that different images may have similar color histograms. This is apparently the case with the middle and right images of Figure F1.
Another way of expressing that phenomenon is to think of the mapping of image into a set of features as a hashing process. The way such mapping are done results into too many hashing collisions. Images of quite different nature are mapped into the same features. (For example all six images of Table C1 in Appendix C are mapped into the same histogram based features.)
It would be possible to obtain a result closer to human intuition by using image segmentation and features such as SIFT or similar [CBGM02, CMMPY00, SZ08]. However, such methods, while fixing the problem illustrated in Figure F1, they might still leave relevant pictures unmatched, for example those shown in Figure F2 because the pose of the object of interest is quite different than in Figure F1 (A). Note added on July 9: I have posted results that confirm that while matching SIFT keypoints can meet the first part of the challenge, it cannot meet the second.
I welcome been corrected by someone with a system where the example of the image shown in the left of Figure F1 will extract from my collection the image in the middle of Figure F1 and those in Figure F2. (I have a separate posting of this challenge on the web).
|
|
D | E |
| Figure F2: Two pictures containing the same dog as in Figure F1. | |


In retrospect the disappointing quality of the results is not surprising. Searching a collection of images for those containing a particular object is equivalent to solving several pattern classification problems. There is a large literature on selecting the appropriate features and several methodologies have been discussed. I will limit my examples here from optical character recognition (OCR), partly because of my familiarity with the area and partly because there are several good quality commercial products. (My favorite is Cuneiform 99.)
Quite early, it was recognized that comparing the images of characters to prototypes was inadequate except for very limited domains. Thus it was found more effective to extract high level features, such as strokes, loops, corners, arcs, and the like [PM92, MNY99]. Words and individual characters were described in terms of entities that corresponded with the human definition of symbols. How could one expect to achieve general object matching by using techniques that have been proven inadequate in much simpler image recognition problems?
The first step for dealing with the problem exhibited by Figure F1 (left
and middle images) and by Figure F2 is to have a classifier that would
recognize that both images contain a dog. Until then no real progress
can be made.
Back to the Table of Contents
3. The Curse of Dimensionality and the lack of Scalability
Several authors do treat CBIR as a classification problem by dividing images into classes such as "animals", "buildings", etc and then retrieving images from the same class as the query image. However queries of this type are not particularly interesting. People are less likely to ask for “all pictures of buildings” and more likely to ask for a picture of a particular building. Furthermore, an image may belong to several categories.
The major weakness of such approaches is that do not heed another lesson from Pattern Classification, namely that increasing the number of features can be detrimental in a classification problem, a phenomenon usually called the "curse of dimensionality". Duda and Hart [DH73 p. 95] attribute the term to Richard Bellman although the Pattern Classification literature uses it in a different way than Bellman did. Let d be the number of degree of freedom of the classifier. If the classifier is linear d equals the number of features F, otherwise it is greater than F. If n is the number of training samples, then for n equal to 2(d+1) there is 50% probability that successful classification can be obtained with a random assignment of two classes on the sample points. Such a success can be called spurious classification and the classifier is likely to fail on new samples. This issue is discussed at great length in Chapter 3.8 ("Problems of Dimensionality") and other parts of [DH73] as well as in Chapter 4.3 ("Parzen Windows") of [DHS01]. For this reason it has been the practice to select the number of samples per class to be considerably greater than the number of features, usually five or even ten times as many.
In general, representing images by features corresponds to a projection from a very high dimensional space (space of all possible images of given dimensions and pixel depth) to the much lower dimensional feature space (recall Section 2). Ideally, we would like images in a given semantic category to project in nearby points in the feature space. If the number of samples is small compared to the dimension of the space, then we might be able to find rules to associate the feature sets of "similar" images even if no real clustering occurs. But when new samples are added, it is unlikely that such an association will prevail. This is the intuitive interpretation behind the analyses cited in the previous paragraphs.
This type of problem occurs even under different formulations of CBIR. Some authors treat features as words and associate images that share many such "words" (for example, [MSMP99] and [SZ08]). The source of the difficulty here is that image parts that may have different human interpretations may map onto the same feature. (Such likelihood varies with the method, it is more likely with the features used in [MSMP99] than with those used in [SZ08] but it is always there.) When the method is tested only on a few thousand known pictures such conflicts are unlikely to occur. (And if they do, the authors are likely to modify their system while preparing the publication of a paper.) But such conflicts are quite likely to occur in large-scale tests.
It might be useful to provide an analogy of this problem in text retrieval. Suppose that we decide to use only the first three letters of each word. Thus "app" would be mapped to "apple", but also to "application", "apparition", "apparel", etc. If one tries this method on a small collection that includes mostly articles on food, the abbreviation will work fine, but it will fail in general. You can run experiments of this kind in Google Desktop and Google and you are likely to find out that a coarse search will work fine in the former but not in the latter. (See also Section 5.)
There is another issue involved in the selection of training samples. They need to be representative of the population, a requirement that is much harder to satisfy unless we understand something about the structure of the classes. For example, in a multifont OCR system we must include samples of all expected fonts as well as samples from documents printed by all expected types of printers.
If a system is going to rely on features, they should be selected parsimoniously to avoid spurious success in the learning set and failure in tests (the curse of dimensionality). It seems that most reported CBIR research places great emphasis on color but color is less important for conveying information than it appears at first. Each color has different luminance and two-color displays where both colors have the same luminance are hard to discern. This phenomenon is called isoluminance (see [Bach_2] for an impressive demonstration) and its existence implies that an image search based only on luminance is not going to be significantly inferior to a search that includes colors. For the same reason the JPEG standard uses twice the resolution for luminance as it does for chrominance. The ability of color blind people to deal quite well with most tasks of daily life as well as the ability of everybody to obtain information from "black-and-white" images offer additional support to this view. Adding color increases the number of features without improving significantly the semantic information carried by features.
Appendix B offers a simulation of what are the
effects of the "curse of dimensionality". Impressive results
in the author's paper are followed by poor results in field tests.
Back to the Table of Contents
4. The Role of Context
In some ways the above example presents too easy a challenge. If a person is asked to label the first two images in Figure F1 and both images in Figure F2 the word "dog" is likely to be the first label. However, a useful CBIR system must also deal with images of ambiguous meaning.
A well-known observation from research in vision is that humans rely a lot on broad context and are likely to ignore local details. This is illustrated in Figure F3 and it suggests that reliance on low-level measurements may produce results different from those of a human viewer. (We miss the forest because of the trees).
Bela Julesz [Ju91] stated that "in real-life situations, bottom-up and top-down processes are interwoven in intricate ways," and that "progress in psychobiology is ... hampered ... by our inability to find the proper levels of complexity for describing mental phenomena". According to V. S. Ramachandran “Perceptions emerge as a result of reverberations of signals between different levels of the sensory hierarchy, indeed across different senses” ([RB98], p. 56). Ramachandran is explicitly critical of the view that “sensory processing involves a one-way cascade of information (processing)” [ibid]
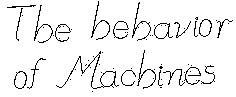 |
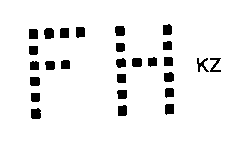 |
| Figure F3: Left: Can you find the spelling error in the text? Right: People ignore the gap between the dots in FH but notice the much smaller gap between K and Z. (Both figures have been adapted from [Pa94].) | |
The human visual system is able to ignore local cues once a high level
interpretation has been achieved. Also consider the two sentences:
New York State lacks proper facilities for the mentally
III.
The New York Jets won Superbowl III.
The last word in each sentence is interpreted differently, even though
they are identical. Such occurrences are even more likely in pictures.
Context has been a major challenge to Artificial Intelligence research overall and the Nobel laureate Arno Penzias has put very succinctly: “Human intelligence almost always thrives on context while computers work on abstract numbers alone. … Independence from context is in fact a great strength of mathematics.” [Pe89, p. 49]
If context is known, then one can include that knowledge in the design the system but this possible only when we deal with a specific application area. In one industrial applications case [PJHHL06] context was used to design, in essence, a top-down vision system. In general we face the formidable problem of context inference that is usually dealt by combining top down and bottom up approaches. There is considerable research in this area but it is beyond the scope of this paper to discuss such literature.
Once we recognize the importance of context, there is at least one simple requirement for techniques for image retrieval: It is not enough to look at parts of an image, we must also look at the overall composition. [FSGD08] offers an example of improved retrieval by including object relationships in a medical application.
5. Why is Image Retrieval so Hard Compared to Text Retrieval
The fundamental reason that CBIR (and mechanical analysis of images in general) is so hard is that it faces the challenge of matching the human visual system that has evolved from animal visual systems over a period of more than 100 million years. In contrast, speech is barely over 100 thousand years old and written text no more than 10 thousand years old. The great complexity of the visual system is detailed, amongst other places, in [RB98], Chapter 4, where it is pointed out that the brain has models of the world (p. 68) and 30 distinct areas, each performing a different type of information processing, such as detecting color, texture, etc (p. 72). The complexity of the system may be also be inferred from the existence of visual illusions. (See [Bach_1] for a large collection with scientific explanations.) While auditory illusions exist, they are far less common than optical illusions.(See [DD95]. I am grateful to Professor Michael Bach of the University of Freiburg for pointing out the existence of auditory illusions and the above reference.)
An operational reason for the difficulty is that the image data (values of pixels stored in bytes) are very far from the interpretation of images by human observers. This is not the case with text where the stored data are much closer to human interpretation.
The following point is so obvious that it would not be worth mentioning, if it were not for the fact that much research in CBIR seems to ignore it. Text consists of words that are well-defined models of concepts so that communication amongst humans is possible. While words may be ambiguous, they are usually easily specified by content. Thus "dog" may mean either an animal or an unattractive person, but if we look at the words surrounding it, the meaning usually becomes clear. In turn, words have a formal representation either by single symbols (in Chinese for example) or by a sequence of symbols (in most languages). Whether one or several, the symbols have a well-defined representation in terms of bits, so going from digital storage to a human understandable representation is a matter of table look up. Therefore finding all files containing the word "dog" is a task of (conceptually) simple string matching. (The Unix command fgrep " dog " filenames does that.) Regular expressions that allow variations in the spelling and delimiters of words make it easier to identify files where the word dog occurs (the Unix grep).
In text retrieval system users are free to compose queries using several words but this not the case with image retrieval where the user is usually asked to provide a query image or a sketch. Some researchers have recognized this and solutions include area selection in an image [Like], semantic labels [RMV07], and the use of multiple images as well as feedback [IA03]. All these approaches improve the performance of an image retrieval system. However the challenge remains because the user must perform some image manipulation work, a more demanding task than typing words.
A fairer comparison between image and text retrieval is to consider retrieval not of words but of concepts. It turns that the state of the art of text retrieval based on concepts is not particularly advanced.
Suppose that I am not looking for stories about any dog but for stories about a dog named Lucy. The task is much harder but Google Desktop did a good job when I asked it to search for "dog Lucy" on my PC. It seems to have identified all files containing either word, which was fine for my purpose. (There were six returns, five of which were what I was looking for.) Google did not do as well because it looks at a much bigger collection of documents. In a large collection even files with both words may be false positives. For example: "Ask Lucy - How to feed a senior dog". However the first 20 (out of close to two million hits) were all true positives. False positives sneaked in after No. 22. True positives were found after No. 70 and I did not look after No. 80. Note that if I ask it to search for "dog named Lucy" I miss a lot of files because many of them do not contain the word "named". We even get results such as: Lucy and I spent the weekend alone together. We have a dog named Kyler. Asking to search for the exact phrase "dog named Lucy" yields about 4,000 hits and less than 250 are shown (the others assumed to be duplications). No false positives but a lot of false negatives. Of course, in all such searches we will miss stories where the word "dog" has been replaced by the name of the breed.
The drop in performance from Google Desktop to Google is what we also observe in CBIR systems when going from the authors’ collection to large public databases.
Another example of the poor state of the art in text filtering is the challenge is to design a filter for material inappropriate for young children. A story with the phrase "she took off her shoes and lifted her skirt in order to cross the flooded street" is probably quite appropriate. On the other hand the words in italics are also likely to appear in objectionable stories. Note also that each of the italicized words is not objectionable on its own.
Searching text by content is quite hard when the content we are looking
for is a concept rather than a phrase. A computer search is effective
only as long as we look for byte patterns. In the case of text, words
are mapped easily into byte patterns, so searching for words is effective.
This should give us a hint why content-based image searching is hard.
The counterpart of searching for words is searching for pixels of a particular
color, not a particularly interesting query.
Back to the Table of Contents
6. What Can We Learn from Success in Other Areas
Practical successes in the overall field of Artificial Intelligence (AI) have been relatively few, but we can learn a lot from them. Not surprisingly, all successes have been in what Hubert Dreyfus calls Weak AI.
Considerable work in "simple" OCR algorithms that could run fast enough on machines of the 1960's or 1970's turned to be a waste of time. Such techniques could not provide satisfactory performance for multifont text and by 1990 there were machines fast enough to implement more "complex" algorithms. There were also issues of scanner resolution. 10 point size text requires at least 300dpi resolution and, again, such scanners did not become available at low price until around 1990. Earlier scanners of 100 or 150 dpi tended to distort images of characters significantly. One notorious case was the mapping of "a", "e", and "s" into a form topologically equivalent to an "8" and recognition efforts relied on slight differences in shape. This problem went away with the introduction of 300dpi resolution scanners.
OCR products also take into account context by using, at least, a spelling checker.
OCR offers another, particularly appropriate, example. For several years published papers reported recognition rates of 97-98%. However such a recognition rate is useless in practice because it corresponds to over 50 errors per page! In addition, many authors did not distinguish between rejection and substitution errors. For a practical system the recognition rate on good quality print should be at least 99.9% (2-3 error per page) and the errors should be rejections (rather than substitutions) so that the system can flag them. The tolerable rate for substitution errors is much lower. George Nagy and Bob Haralick wrote a lot on that topic for anyone interest to read more.
An Aside on Accuracy
The accuracy issue is particularly pertinent to image retrieval where all too often we see publications claiming success rates anywhere from 60% to 90%. Such rates are clearly better than random guesses but it is unclear how useful they are. There is often no distinction between false positives and false negatives. For example, in a forensic application we may tolerate several false matches as long as we do not miss any true match. The casual handling of this issue in the literature temps me to offer a variation on the old joke "How a physicist proves that all odd numbers are prime". An image retrieval person's proof: "3 is prime, 5 is prime, 7 is prime, 9 hmm, 11 is prime, 13 is prime, oh well, we have an 83% success rate, let's publish."
Chess playing programs offer another example of the importance of computing power. As long as people were relying on human inspired heuristics, chess playing programs were weak. A breakthrough occurred in the late 1970’s with Ken Thompson’s Belle that relied on special purpose hardware taking advantage of the raw search power of machines. Eventually, this led to the Deep Blue that in 1997 defeated the human world champion. The following is from an interview of Murray Campbell (one of the Deep Blue designers) [Ca07]: “There was a turning point in the '70s when it was realized that, if you let computers do what they do best -- that is, search through as many possibilities as they can as quickly as they can -- and stop the pretense of trying to emulate how humans play, you actually got better performance. And so, from that day on, computers, including Deep Blue, tended to be focused on searching through as many possible chess moves as they could in the amount of time that was available for a computation.” We may have to wait for special purpose image processing hardware (probably multiprocessor networks) before we can make truly significant progress in the general image analysis area.
Speech recognition provides an example where prior knowledge about the structure of the signal is critical for success and this argues in favor of restricting image analysis (including CBIR) research to special areas. Speech recognition systems are now available in many telephone services (for example the American Airlines reservation system provided by TellMe) and they are all grammar driven, in other words high level knowledge about human language drives the recognition system (see for example [KGRMKL01].) Using spatial context for image labeling has been helpful [SLZ03] but currently there are too few well defined rules that are valid for large classes of images. (Grammatical approaches have been used in pattern recognition with limited success because the two-dimensional structure of images does not offer itself to grammatical models the human languages do.)
In the area of image analysis there is another important characteristic
of successful applications. They tend to be in situations where human
recognition relies on the meticulous study of details rather
than a general overview of the scene. People have trouble with the former
task but they excel at the latter (the adaptive significance of the difference
in abilities is obvious). Thus image analysis has found successful applications
in industrial inspection and biometrics, especially fingerprint recognition.
Automatic fingerprint identification (retrieving a match to a fingerprint
from a database) is used in practice by the FBI
and there are several commercial products for fingerprint verification
(checking whether two fingerprints are the same), for example by Zvetco.
(The mention of such systems attests only to their existence, rather than
to their specific abilities.) In both industrial and biometric applications
the mapping of images to features was well understood and the main challenge
has been the reliable extraction of such features from the image (for
example, the minutiae in the case of fingerprints).
Back to the Table of Contents
7. What to Do
Clearly, the general CBIR problem is well beyond the current approaches and it may well turn out to be intractable in the foreseeable future. In contrast to text retrieval that relies on linguistic expressions of human concepts, there is no well defined set of rules to formalize the content of images. For any automatic image processing we need a mapping between human impressions ("semantics") and quantities that can be computed ("features"). Successful pattern recognition relies on such quantities. Statistical techniques may be used for fine-tuning the parameters necessary to design such features, but they cannot uncover the structure of the mapping. In generating such features we must also specify the classes of images we are dealing and this, in turn, facilities the proper selection of "learning" samples.
[DAL08] describe a classification of the obstacles to CBIR that has many merits, but I prefer a more basic approach based on the arguments I used over 35 years ago when I introduced Structural Pattern Recognition [Pa72]. The most important step is to understand the nature of the problem and how the image can be transformed into a mathematical representation without loss of information about what we consider to be the important aspects of an image. For the case of OCR the important elements were strokes and their spatial relationships (but not their color, or, within limits, their thickness.) If color and texture are important (for example, to identify a lesion in a medical image) then we need texture and color descriptors that are accurate enough to represent uniquely the textures and colors of interest.
I believe that a CBIR problem that fits the following characteristics is a good candidate for solution within the current state of computer technology.
- The mapping between semantics and image features is well
defined. This way the issue of "semantic gap"
is put to rest. The representation by features can be made without loss
of information, in such as way so that only images with similar interpretation
and no others are mapped into the same set of features. (Examples abound
in the pattern recognition literature, including OCR and fingerprint
recognition.)
- The context is known. For example, we may
know that the object of interest occupies a particular area in the image
or is close some other well defined feature. The context
can be taken advantage in the design and selection of the features.
- The matching of images requires careful scrutiny.
This is a process that humans are not very good at and it is likely
that machines can match or even exceed human performance. Medical, industrial,
forensic, security, as well as other applications seem to offer problems
of this type.
- The accuracy requirements are well defined.
Knowing the relative significance of false matches versus omitted true
matches is particularly important.
- The computational requirements are well defined. In many cases instant response is not needed. For example, in a medical application it may take well over an hour to produce an image, so waiting another hour to find matches in a database is not particularly onerous. In security applications a fast response is often necessary but in that case the database is proprietary (not a public collection) and it may organized accordingly for fast retrieval.
I do not see how we can have a mathematical representation without loss of information for the general category of "all images" but we have a good chance of achieving that by confining the problem into retrieving images from a particular category only (for example, matching an iris scan to a collection of iris scans).
Biometric applications are probably where most progress has been made (as stated in Section 6) and research is now continuing in more challenging soft biometrics such as the matching of tattoos and scars [LJJ08].
Medical applications appear particularly appropriate because the images are searched for objects (for example, lesions) for which there is usually no intuitive human definition and comparisons between a query image and the database can be quite laborious for a human. However according to [DAL08] there have been no hospital applications, apparently because the methodology used has been "general" without taking advantage of the specifics of the applications. A recent work [FSGD08] deals with a the identification of hand bones, and it describes improvements in performance by taking advantage of the spatial relationships between the bones and using inexact subgraph matching.
I also noticed recently the following description of a project directed by Professor Bob Fisher of the University of Edinburgh: "The project goal is to develop an interactive skin cancer image database indexing tool, where users compare 'live' skin lesions/spots to images selected from a database. Based on user feedback on the appropriateness of the selections, the database will be searched for better matches." The specificity of the application makes likely the development of semantically meaningful features.
Another potential area of successful CBIR is in reconnaissance and surveillance either for security purposes or natural resource management. Over ten years ago we used a graph representation and shape features for branches to retrieve information from road maps [HP96] that could match the location of an aerial photograph to a particular geographic area.
My list of areas is far from exhaustive. As long as the objects we are looking for in a set of images can be characterized accurately by computable features the area is ready for CBIR development within the current state of computer technology.
It is important that the images and objects of interest be characterized formally so the results can be scalable. The use of a standard set of images may be fine for the initial stages of the research but the algorithm must soon be tested on any image that satisfies appropriate criteria. Let me digress here for a moment. I have worked in industry where an imaging product is tested in the customer's site with blue collar workers (as opposed to graduate students) handling the equipment and, while hard, it is quite possible to design systems that perform well in an unlimited testing set (for example [PJHHL06]).
Evaluation of methodologies solely on the basis of statistical results of their performance on "standard sets" is fraught with risks because of the difficulty of ensuring that the membership of the set and the rules of evaluation are representative of the real world where the methodologies will be applied. See, for example, [Io05]. Even though [Io05] address mainly medical studies, several of the issues it raises are also relevant to pattern recognition. It is important to pay close attention to what is considered a satisfactory performance.
I believe it is the lack of proper testing that contributes
to the paradox raised by [HLMS08]: "Multimedia Information Retrieval:
So Close or Yet So Far Away?" It is close if we look at published
method that work well on a specific data set. It is far away, if we realize
that many such methods work only on a specific data set. In the age of
the internet it is essential to subject methodologies to public testing.
Back to the Table of Contents
8. Conclusions
I believe that until there is sufficient progress in object recognition or in application specific CBIR, general CBIR research is unlikely to be fruitful, especially when constraints on real time performance are added. (Such constraints tend to limit systems to global features that cannot meet even the simple challenge illustrated in Figure F1.) If we start with problems fitting the five properties listed in the previous section, then we may have a hope of not only solving specific problems, but also gaining insight on what methodologies are most appropriate.
If I were forced to work on general CBIR, then I would look to extend current approaches that rely on the search for objects by creating "visual words" (for example, [LJSJ08] and [SZ08]). Both of the cited papers rely on matching sets of key points obtained by SIFT [Lo04]. However, I doubt that such features can deal with shadows and differences in pose (as exemplified by the images of Figure F2). (Indeed [Pa08] suggests severe limitations of SIFT for general images although it seems useful for images of 2D objects.) A critical extension of such work would be to tag such visual words with object names and they search for name matches. Because different visual words may map on the same name, fewer matches will be missed. Such labeling will be bridging in effect the "semantic gap". It would be interesting to investigate whether approaches based on segmentation (for example [CBGM02]) or graph matching (for example [Pt02]) face a higher threshold in overcoming differences in pose and distractions like shadows than methods based on key points. Extensive interaction with the user as described in [HSHZ04] is bound not only to help in performance but also provide insight in the utility of features. The importance of user feedback has been documented by several other authors (for example, [IA03]).
Several authors have been combining text tags of images with features [RMV07]. This is certainly a valid approach, provided that the features used provide really useful information. However global statistics are unlikely to help because of they are so far from the semantic interpretation. Instead of providing semantic tagging to make up for semantically unreliable features it might be better to look for features that are closer to semantics.
I would stay away from over-reliance on statistical "learning" techniques that has plagued not only CBIR but machine vision and pattern recognition in general. Besides the issues discussed in Sections 3 and 6, such techniques obscure the understanding of the solution to a problem. Of course, being able to solve problems without understanding them is seductive but it is not conducive to good science. Unfortunately, to paraphrase Langmuir [La53], the seduction is so strong that such pathological science is not likely to go away any time soon.
I should emphasize that the problem is not caused by the statistical techniques themselves but by the way they are applied. Studying the nature of the classification problem and deriving high level features (the core of structural pattern recognition) allows classification with relatively few such complex features which in turn reduces the needed number of training samples. Statistical techniques are then used for fine tuning the classification (see for example, [KPB87]).
Humans (and animals) are able to learn from very few samples while machines
cannot. This issue has challenged researchers and [FFP06] is a paper that
attempts to deal with that issue although I do not think it captures the
real mechanism that is used in natural systems. [RB98] states that "Rats
trained to distinguish between a square and a rectangle perform quite
well when faced with skinnier rectangles. They have the concept of rectangle!"
So when animals and humans are faced with an example, they form a concept
that allows them to extrapolate in future situations. The biological adaptive
significance of such ability is obvious! The ability of humans to identify
objects or persons from very rough sketches is remarkable. (I should add
that recent research [MJ06] has cast doubts on Ramachandran's interpretation.
However the fact that humans can learn from very few samples still stands.)
Back to the Table of Contents
9. Acknowledgements
A first draft of my discussion of CBIR was posted on my web site in June 2007. That draft underwent several changes (I was more optimistic about the future of general CBIR in the beginning). I want to thank David J. Liu of VIMA and Qasim Iqbal of the University of Texas for comments on earlier drafts and additional pointers to the literature. Several others provided me with pointers to research work and publications and/ or answered my questions about their work. They include Amanda Stint of Stony Brook University, Stephen Horowitz of Yahoo, Nuno Vasconcelos of UC San Diego, Stephane Marchand-Maillet of the University of Geneva, Ingemar Cox, Benedikt Fischer of the University of Aachen, Bob Fisher of the University of Edinburgh, Rahul Sukthankar of HP Research and CMU, Andrew Lampert of CSIRO and Anil Jain of Michigan State University.
The listing of these people here does not imply in any way that they share the views expressed in this document.
10. Sources Cited
| [Bach_1] | http://www.michaelbach.de/ot/ |
| [Bach_2] | http://www.michaelbach.de/ot/col_isoluNuBleu/index.html |
| [Ca07] | Interview by Wired News |
| [CBGM02] | C. Carson, S. Belongie, H. Greenspan, J. Malik "Blobworld: Image Segmentation Using Expectation-Maximization and Its Application to Image Querying" IEEE Trans. PAMI, vol. 24 (8), 2002, pp. 1026-1038. |
| [CMMPY00] | I. J. Cox, M. L. Miller, T. P. Minka, T. V. Papathomas, and P. N. Yianilos, "The Bayesian Image Retrieval System, PicHunter: Theory, Implementation, and Psychophysical Experiments" IEEE Trans. on Image Processing, vol. 9 (1), 2000, pp. 20- 37. |
| [DAL08] | T. M. Deserno, S. Antani, and R. Long "Ontology of Gaps in Content-Based Image Retrieval", Journal of Digital Imaging, 2008. A preliminary and shorter version appeared in SPIE Proc. vol. 6516 (2007). |
| [DD95] | Diana Deutsch's Audio Illusions. These illusions were first demonstrated in the 1970's. | [DH73] | R. O. Duda and P. E. Hart Pattern Classification and Scene Analysis, Wiley, 1973. |
| [DHS01] | R. O. Duda, P. E. Hart, and D. G. Stork Pattern Classification, 2nd edition, Wiley, 2001. |
| [FFP06] | Fei-Fei, L., R. Fergus, and P. Perona “One-Shot Learning of Object Categories”, IEEE Trans. PAMI, vol. 28 (2006), pp. 594-611. |
| [FSGD08] | B. Fischer, M. Sauren, M. O. Güld, and T. M. Deserno "Scene Analysis with Structural Prototypes for Content-Based Image Retrieval in Medicine", Proc. SPIE Conf. No. 6914, 2008. |
| [HLMS08] | A. Hanjalic, R. Lienhart, W-Y Ma, and J. R. Smith "The Holy Grail of Multimedia Information Retrieval: So Close or Yet So Far Away?" IEEE Proceedings, Special Issue on Multimedia Information Retrieval, 96 (4), 2008, pp. 541-547. |
| [HP96] | J. Hu and T. Pavlidis ``A Hierarchical Approach to Efficient Curvilinear Object Searching,'' Computer Vision and Image Understanding, 63 (March 1996), pp. 208-220. |
| [HSHZ04] | L. Huston, R. Sukthankar, D. Hoiem. and J. Zhang "SnapFind: Brute Force Interactive Image Retrieval" Proceedings of International Conference on Image Processing and Graphics, 2004. |
| [IA03] | Q. Iqbal, and J. K. Aggarwal “Feature Integration, Multi-image Queries and Relevance Feedback in Image Retrieval”, Proc. VISUAL 2003, pp. 467-474. |
| [Io05] | John P. A. Ioannidis "Why Most Published Research Findings Are False" Public Library of Science - Medicine 2(8): e124, 2005. |
| [Ju91] | B. Julesz "Early vision and focal attention", Reviews of Modern Physics, vol. 63, (July 1991), pp. 735-772. |
| [KPB87] | S. Kahan, T. Pavlidis, and H. S. Baird, ``On the Recognition of Printed Characters of Any Font And Size'', IEEE Trans. on Pattern Analysis and Machine Intelligence, PAMI-9 (1987), pp. 274-288. |
| [KGRMKL01] | Knight, Sylvia / Gorrell, Genevieve / Rayner, Manny / Milward, David / Koeling, Rob / Lewin, Ian (2001): "Comparing grammar-based and robust approaches to speech understanding: a case study", In EUROSPEECH-2001, 1779-1782. |
| [La53] | I. Langmuir "Pathological Science" Colloquium at The Knolls Research Laboratory, December 18, 1953. Transcribed and edited by R. N. Hall. Web Posting |
| [LJJ08] | J-E. Lee, A. K. Jain, R. Jin "Scars, Marks, and Tattoos (SMT): Soft Biometric for Suspect and Victim Identification" Biometrics Symposium, Tampa, Sept. 2008. |
| [Lo04] | D. Lowe "Distinctive Image Features from scale-inavariant keypoints" Int. J. Comp. Vision, 2004. |
| [LJSJ08] | Y. Liu, R. Jin, R. Sukthankar, F. Juri "Unifying Discriminative Visual Codebook Generation with Classifier Training for Object Recognition". Proceedings of Computer Vision and Pattern Recognition Conference, 2008. |
| [Like] | http://www.like.com |
| [MJ06] | L. Minini and K. J. Jeffery 'Do rats use shape to solve "shape discriminations"?' LEARNING & MEMORY 13 (2006) pp.287-297. Also on line. |
| [MNY99] | S. Mori, H. Nishida, and H. Yamada Optical Character Recognition, Wiley, 1999. |
| [MSMP99] | H. Müller, D. Squire, W. H. Müller. and T. Pun "Efficient access methods for content-based retrieval with inverted files", 1999. On Line. |
| [Pa72] | T. Pavlidis, "Structural Pattern Recognition: Primitives and Juxtaposition Relations", Frontiers of Pattern Recognition, (M. S. Watanabe, ed.) Academic Press (1972), pp. 421-451. |
| [Pa94] | T. Pavlidis "Context Dependent Shape Perception", in Aspects of Visual Form Processing, (C. Arcelli, L. P. Cordella, and G. Sanniti di Baja, eds.) World Scientific, 1994, pp. 440-454. |
| [Pa08] | T. Pavlidis, An Evaluation of the Scale Invariant Feature Transform (SIFT), August 2008.Web Posting. |
| [PJHHL06] | T. Pavlidis, E. Joseph, D. He, E. Hatton, and K. Lu "Measurement of dimensions of solid objects from two-dimensional image(s)" U. S. Patent 6,995,762, February 7, 2006. Discussion of the methodology and links to sources on line. |
| [PM92] | T. Pavlidis and S. Mori, Special Issue on Optical Character Recognition, IEEE Proceedings, vol. 80, No. 7, July 1992. |
| [Pe89] | Arno Penzias Ideas and Information, Norton, 1989. |
| [Pt02] | E. G. M. Petrakis "Design and evaluation of spatial similarity approaches for image retrieval" Image and Vision Computing, vol. 20 (2002), pp. 59-76. |
| [RB98] | V. S. Ramachandran and S. Blakeslee Phantoms in the Brain, William Morrow and Company Inc., New York, 1998 |
| [RMV07] | Rasiwasia, N., P. J. Moreno, and N. Vasconcelos “Bridging the Gap: Query by Semantic Example”, IEEE Trans. Multimedia, vol. 9, 2007, pp. 923-938. |
| [SBTDM02] | U. Sinha, A. Bui, R. Taira, J. Dioniso, C. Morioka, D. Johnson, and H. Kangarloo, " A Review of Medical Imaging Informatics", Ann. N. Y. Acad. Sci., vol. 980 (2002), pp. 168-197. |
| [SLZ03] | Singhal, A.; Jiebo Luo; Weiyu Zhu “Probabilistic spatial context models for scene content understanding” Computer Vision and Pattern Recognition, 2003. Proceedings, pp. I-235 - I-241. |
| [SWSGJ00] | A. W. M. Smeulders, M. Worring, S. Santini, A. Gupta, and R. Jain "Content-Based Image Retrieval at the End of the Early Years", IEEE Trans. PAMI, vol. 22, 2000, pp 1349-1380. |
| [SZ08] | J. Sivic and A. Zisserman "Efficient Visual Search for Objects in Videos", IEEE Proceedings, Special Issue on Multimedia Information Retrieval, 96 (4), 2008, pp. 548-566. |
| [YSGB05] | K. Yanai, N. V. Shirahatti, P. Gabbur, and K. Barnard "Evaluation Strategies for Image Understanding and Retrieval", Proc. ACM MIR, Nov. 2005. |
Back to the Table of Contents