A Solution to a Practical Machine Vision Problem
and its Broader Implications.
T. Pavlidis
© 2007
During a two year period (2000-2002) I worked with my former student Ke-Fei Lu (then employed by Symbol Technologies) and several other engineers from Symbol Technologies on a practical machine vision problem that dealt with the automatic measurement of the dimensions of rectangular boxes. The company received a patent on the system we built [1] and we also published a short paper [2] but the broader methodological features of the work have never been discussed and generalizations of the work were not attempted because of problems with the company that resulted in the closing of its R&D organization.
The specific problem we solved is a special case of using mid-level context in image analysis. From the very beginning researchers had distinguished bottom-up and top-down approaches but, eventually, it became evident that we needed a combination of both [3]. The need for such an approach became quite clear in Optical Character Recognition (OCR) and I have discussed this issue in an old paper [4] that also contains references to earlier works. A bottom-up OCR approach would use no dictionary or other linguistic information. A top-down approach tries to much each word found in a dictionary. This technique is used in many commercial systems but it has serious limitations that are discussed in [4]. What would help is to form an idea of what the subject of the discourse is (i.e. infer the context) and then modify the bottom up OCR results accordingly. My favorite example consists of the words date and dale. The second often appears as a result of missing the short horizontal bar of the letter t in dale but a dictionary look up cannot correct it because it is a legitimate English word. However, if we know that the document is a business letter we are justified in replacing dale by date. If we are dealing with a poem, then we will be inclined to leave dale alone. We would obtain even better results if we were able to parse the sentences of the document. Figure 1 (taken from Figure 8 of [4]) shows the power of context in human reading. Do you think the text reads the "The behavior of Machines"? Is so, look closer. We see what we expect to see. (Move the mouse over the image to read the correct text.)
The big question is "How can we transfer these concepts to the general scene analysis problem?" True context inference is still far away but we can demonstrate how it can be used effectively in the image analysis part of the box dimensioning system.
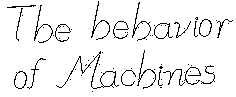
|

|
| Figure 1 | Figure 2 |
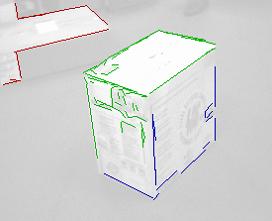
The machine vision problem was to find the outline of a rectangular box from a picture such as that shown in Figure 2 on the right. Note that the box contains a lot of graphics with significant contrast, comparable with the contrast of the box with the background. Therefore edge strength is not a reliable measure of the significance of an edge for the goal of the project. Also there is no way to "train" the system on the kind of boxes that there will be considered because the system was supposed to be open. Customers who bought the device expected it to be usable with any kind of boxes. One key observation was that in the context of the application we can ignore many parts of the image (such as the graphics on the box or the texture of the floor covering) and instead to look only for "large" objects. We also expect the box to occupy the center and most of the area of the scene. This is because the user is aiming the device at the box and when the measurement is completed, the user hears a sound signal (beep). Therefore the user learns quickly how to aim the device. All these observations can be used to design the low lever vision system. This approach can be expressed in general by the statement.
|
"Use top level knowledge to design low level algorithms" |
In the problem at hand this implies that direct long line detection is preferable to edge detection.
I provide here only a broad discussion of the methodology. (Those interested in the full system and in the details of the method should consult the cited sources, [1] and [2].)
The implementation used 8x8 blocks for line fitting. The point P of maximum gradient in each block is found, and a line perpendicular to the gradient and going through P is tried as separator. No attempt to find a line was made if the maximum gradient was too small. The parameters for making these decisions were determined adaptively. The goal was to find no more than a certain number of lines and if too many lines were found, the parameters were adjusted and the process repeated. All the low level vision processing is guided by the knowledge of what we are looking at.
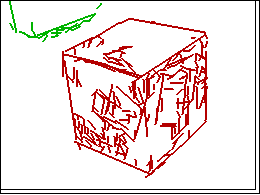
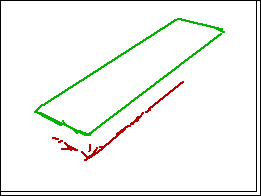
Line segments found in this way are merged into bigger segments and then we form proximity clusters of line segments with the property that they have end points that are close. Figure 3 below shows the line proximity clusters. (On the left is the result for the scene of Figure 2)
 |
 |
 |
| Figure 3 | ||
Because we know that the outline of a rectangular box is a hexagon we expect it to be the convex hull of all the line clusters in the object. Unfortunately, we do not have the information of which clusters are in the same object. The example in the middle of Figure 3 is simple because one of the clusters corresponds to a single object but the others need a bit more work. We construct the convex hull of the set of lines not only in a single cluster but also in combination of clusters and we apply several criteria to select from amongst the convex hulls found. The details are given in [1] and [2].
The main characteristic of this work are:
- The properties of application determined the low level processing:
looking for line segments rather than edges. In particular, we are not
attempting segmentation.
- In the next level we look only for shapes of interest, ignoring other
objects on the scene.
- Significant use of standard algorithms was made. Both the clustering and the determination of the convex hull were done in this way.
The third characteristic is not part of the context based approach, but I bring it here as an example of a methodological approach to simplify a complex problem.
One lesson from this work is that in a general scene analysis system should have several low level vision systems and activate a different depending on what we are looking for. Streamlined approaches, such as segmentation followed by shape analysis do not offer enough flexibility. Approaches without segmentation have been used succesfully in both bar code reading [5, 6, 7] and in OCR [8]. The methods described in the latter references do not attempt to distinguish between "light" and "dark" pixels but instead use gray level information directly.
Works Cited
(Sorry, no electronic version available when there is no link.)
| 1. | T. Pavlidis, E. Joseph, D. He, E. Hatton, and K. Lu "Measurement of
dimensions of solid objects from two-dimensional image(s)" U. S. Patent
6,995,762,
February 7, 2006. |
| 2. | Ke-Fei Lu and T. Pavlidis "Detecting Textured Objects using
Convex Hull" Machine Vision and Applications, 18
(2007), pp. 123-133. Text (PDF) and
Illustrations (PDF) . |
| 3 | T. Pavlidis ``Why Progress in Machine Vision is so Slow,'' Pattern
Recognition Letters, 13 (April 1992), pp. 221-225.
(Based on an invited talk given at ICPR 1986 in Paris.) |
| 4. | T. Pavlidis "Context Dependent Shape Perception"; in Aspects
of Visual Form Processing, (C. Arcelli, L. P. Cordella, and G.
Sanniti di Baja, eds.) World Scientific, 1994, pp. 440-454. |
| 5. | E. Joseph and T. Pavlidis "Bar Code Waveforms Recognition Using Peak Locations"
IEEE Trans. on Pattern Analysis and Machine Intelligence, 16
(June 1994), pp. 630-640. |
| 6. | S. J. Shellhammer, D. P. Goren, and T. Pavlidis "Novel Signal Processing
Techniques in Bar Code Scanning," IEEE Robotics and Automation Magazine,
6 (1999), pp. 57-65. |
| 7. | Advertisement
for "Fuzzy Logic" Scanner |
| 8. | J. Rocha and T. Pavlidis "Character Recognition without Segmentation,"
IEEE Trans. on Pattern Analysis and Machine Intelligence, 17
(Sept. 1995), pp. 903-909. |